AI Full-Stack
Co-Refine
An AI-augmented qualitative coding platform that helps researchers maintain coding consistency through real-time audit alerts, deterministic embedding similarity, constrained LLM feedback, visual analytics, and collaborative inter-coder reliability workflows.
Overview
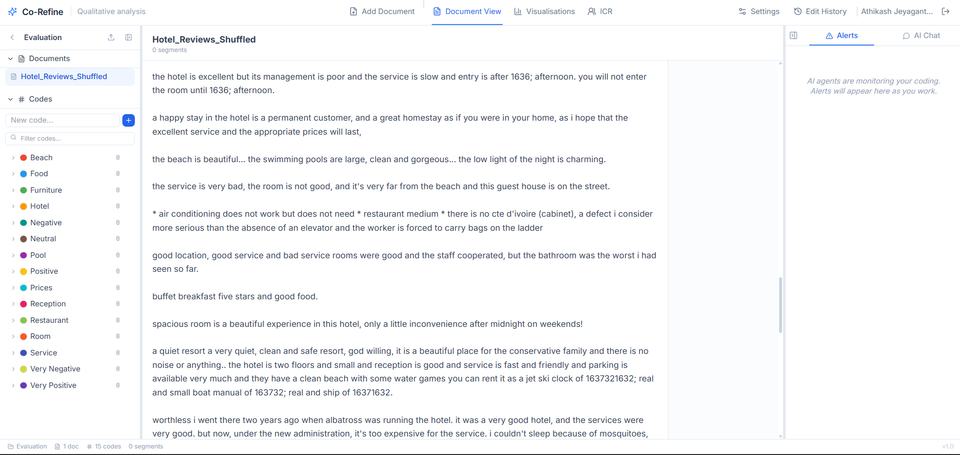
Co-Refine is a full-stack AI research platform designed to support qualitative researchers during thematic analysis and coding. Instead of automating interpretation, the system acts as a reflective assistant that helps researchers identify when their use of a code begins to drift, overlap with another code, or conflict with previous coding decisions. The platform allows users to create research projects, upload qualitative documents, build and manage a codebook, select text spans, and apply codes directly inside the browser. Each coding decision is persisted and automatically audited in the background so that researchers can continue working without waiting for AI analysis to complete. The core technical contribution is a three-stage audit pipeline. Stage 1 calculates deterministic embedding-based metrics, including centroid similarity and temporal drift, to measure how well a newly coded segment aligns with previous examples. Stage 2 passes these grounded signals to an LLM, constraining its consistency score within a fixed tolerance of the deterministic evidence to reduce hallucinated or arbitrary scoring. Stage 3 uses accumulated coding patterns to synthesise refined code definitions, allowing the system’s understanding of each code to evolve alongside the researcher’s own interpretation. Co-Refine also includes analytics dashboards for monitoring coding quality over time. These include consistency timelines, code overlap heatmaps, co-occurrence matrices, t-SNE facet exploration, and AI-suggested sub-theme labels. For collaborative research teams, the system supports project membership, per-user vector collections, inter-coder reliability metrics such as Cohen’s Kappa, Fleiss’ Kappa, and Krippendorff’s Alpha, and a structured disagreement-resolution workflow. This project demonstrates applied AI engineering across backend architecture, vector search, LLM orchestration, real-time WebSocket feedback, frontend state management, evaluation design, and responsible human-in-the-loop AI. It was built not as a generic chatbot wrapper, but as a domain-specific AI system where model outputs are grounded in deterministic evidence and designed to preserve researcher control.
Problem
Qualitative researchers often apply codes across large volumes of interviews, survey responses, documents, or field notes. Over time, the meaning of a code can unintentionally shift as the researcher’s interpretation evolves. This “temporal drift” is difficult to detect manually, especially when projects involve hundreds of codes, long datasets, or multiple collaborators. Existing qualitative data analysis tools provide document management, codebooks, highlighting, retrieval, and some collaboration features, but they largely rely on researchers to manually review previous coding decisions. This creates three major issues: coding drift is usually discovered too late, semantically overlapping codes accumulate over time, and manual consistency review becomes impractical at scale. Co-Refine addresses this by auditing each coding decision in real time, giving researchers immediate, explainable feedback while preserving their authority over the final interpretation.
Role
Sole AI software engineer, full-stack developer, and researcher. I designed and implemented the system end to end, from requirements elicitation and technical architecture through backend development, frontend implementation, AI pipeline design, vector-store integration, testing, and evaluation.
Constraints
The system had to preserve researcher control rather than automate qualitative interpretation. AI outputs needed to be advisory, explainable, and grounded in the researcher’s own coding history. A major technical constraint was preventing LLM score drift and hallucination. To address this, I designed the audit system so that LLM-generated consistency scores were constrained by deterministic embedding similarity scores. The application also needed to run audits without interrupting the researcher’s workflow, so segment creation triggers background processing and real-time WebSocket updates rather than blocking the UI. Cold-start behaviour was another challenge: new codes may not have enough coded examples to form a reliable centroid, so the system uses code definitions as proxy centroids until enough examples are accumulated. Additional constraints included data privacy concerns for qualitative research, the need for per-user vector isolation, managing thread safety between ChromaDB and SQLAlchemy background tasks, supporting multiple document formats, controlling Azure OpenAI API usage, and delivering the project within a dissertation timeline.
Result
Co-Refine delivered a working AI-augmented qualitative coding platform with the full project workflow implemented: project creation, document ingestion, codebook management, text selection, coding, real-time audit alerts, AI chat, edit history, visual analytics, project settings, and collaborative ICR workflows. The project implemented all stated objectives. The final system supports PDF, DOCX, and HTML document ingestion; deterministic audit scoring; constrained LLM feedback; AI-generated code definition refinement; five major visualisation views; and collaborative metrics including Cohen’s Kappa, Fleiss’ Kappa, and Krippendorff’s Alpha. The audit pipeline was verified against consistent, boundary, and deliberately inconsistent coding examples. The user evaluation achieved a mean SUS score of 77.77, which is above the common usability benchmark of 68. Participants responded positively to the system’s role as a “secondary triangulator” that supports reflection without replacing the researcher. The main novelty of the project is its hybrid deterministic-LLM audit pipeline: Co-Refine combines real-time audit feedback, embedding-based consistency scoring, LLM-grounded explanations, drift detection, and ICR resolution in one workflow.