Reinforcement Learning
Pay the Spread or Earn It: Reward Specification Shapes Execution Policy in RL Limit-Order Traders
Built and evaluated Double DQN limit-order trading agents in the Bristol Stock Exchange simulator to test how reward design changes execution behaviour. The study showed that surplus-based rewards produced a more disciplined “earn the spread” policy with a higher Sharpe ratio, while profit-based rewards encouraged aggressive spread-crossing and more trades but weaker risk-adjusted returns.
Overview
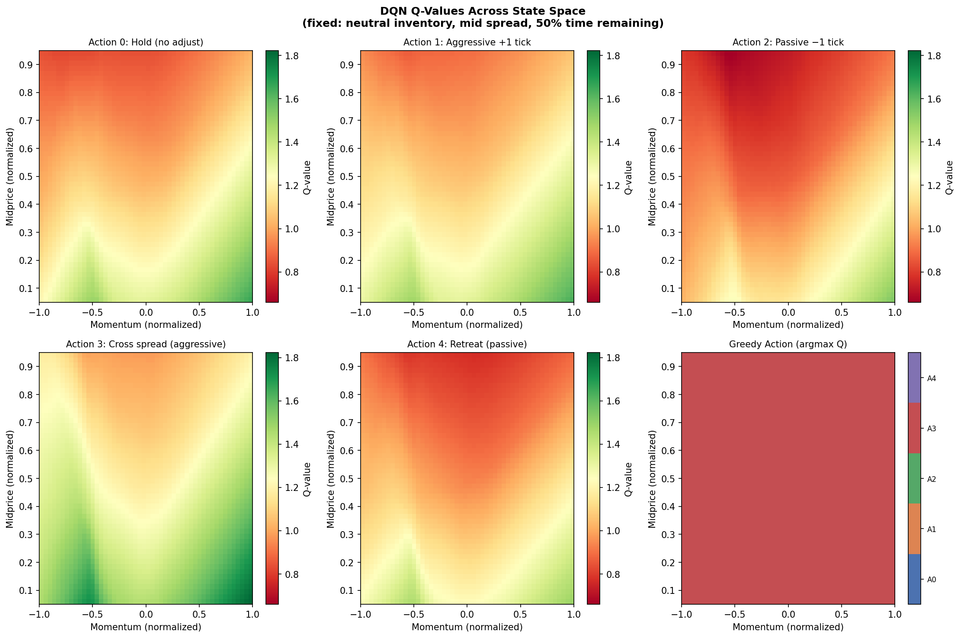
This project investigates whether reward specification alone can change the learned execution strategy of reinforcement-learning traders in a limit-order-book market. Two identical Double DQN agents were trained in the Bristol Stock Exchange simulator, differing only in their reward functions: one used a surplus-aligned reward and the other used a profit-aligned reward with inventory considerations. Their policies were evaluated against ZIP, ZIC, Momentum, and Ensemble baselines across 900 simulated trading sessions and three volatility regimes. The results show that reward design meaningfully shapes trading behaviour. The surplus-reward agent learned to improve quotes by one tick toward the market, effectively trying to earn the spread while preserving execution quality. The profit-reward agent learned to cross the spread more frequently, prioritising immediate execution and higher trade count. Although the profit-reward agent traded more often, the surplus-reward agent achieved stronger risk-adjusted performance, with a Sharpe ratio of 5.94 compared with 4.67.
Problem
RL trading research often focuses on model architecture, state representation, or exploration strategy, while treating the reward function as an implementation detail. This project addresses the problem that, in limit-order trading, small changes in reward design can cause agents to learn very different execution behaviours, affecting fill rate, execution quality, inventory risk, and overall performance.
Role
Researcher, developer, and author. I designed the experimental comparison, implemented and trained the Double DQN trading agents, configured the BSE market simulations, benchmarked against rule-based and zero-intelligence baselines, and analysed the resulting policies using performance metrics, action distributions, entropy, KL-divergence, Q-value analysis, and statistical testing.
Constraints
The experiment had to isolate reward specification as the only experimental variable, keeping the DQN architecture, state space, action space, training setup, and hyperparameters identical across agents. The evaluation was limited to the BSE simulator, homogeneous trader populations, 10 traders per side, 300-second sessions, and a discrete five-action quote-adjustment space. The study also had to test robustness across no-shock, low-volatility, and high-volatility market regimes.
Result
The surplus-aligned DQN achieved the best overall performance, with mean per-trade profit of 21.63 and a Sharpe ratio of 5.94. The profit-aligned DQN traded more frequently, averaging 64.5 trades per session compared with 59.9 for the surplus agent, but achieved a lower Sharpe ratio of 4.67. Policy analysis showed a clear behavioural split: the surplus agent preferred the Agg+1 action in 44.1% of states, while the profit agent preferred crossing the spread in 53.3% of states. Both agents remained robust across volatility regimes, suggesting that the DQN architecture generalised well while the reward function determined execution style.